This basically removes hidden 'all() &' from union/negation of filters. To
achieve that, I have two options: 1. add separate evaluation path (like the
one this commit introduced), or 2. wrap "all()" revset to override predicate
as Box::new(|_| true) function. I took the former since it's less ad-hoc.
We can add an explicit RevsetExpression node to branch between evaluate()
and evaluate_predicate(), but I don't think it would simplify the
implementation at this point. We might need such node if we want to resolve
"all()" at resolve_symbols(). It might be even better to extract a subset of
RevsetExpression enum, which only contains evaluatable nodes.
The cost of 'all() &' isn't significant for most filters. '~merges()' is
the exception. For jj repo,
revsets/:v0.3.0 & (author(martinvonz) | committer(martinvonz))
--------------------------------------------------------------
base 1.06 11.2±0.04m
new 1.00 10.5±0.05m
revsets/~merges()
-----------------
base 1.69 750.0±8.47µ
new 1.00 444.1±3.50µ
I think this is more readable, and apparently it produces slightly better code
maybe because the compiler can determine that there are no unwanted markers.
Since filter is slow in general, its input set should be minimized. This has
measurable impact on artificial query like '~(v0.4.0..) & author(_)'. If it
were evaluated as a difference of sets, all commits would have to be loaded.
This document is meant to be a record of how we think about Git
submodules (and not a _current_ implementation of submodules). We will
fill it out incrementally as we get a clearer idea of what we want
submodules to look like.
As an initial version, I started with (IMO) the least controversial
points:
- We want to support most workflows Git submodules users are accustomed
to.
- A roadmap that allows us to incrementally roll out Git submodule
functionality (instead of having to boil the ocean).
This follows up on 5c703aeb0397b560a383bdd57a87235834074b64.
The only reason for this change is that, subjectively, the result looks better to me. I'm not sure why, but I couldn't get used to the old symbol in spite of its seeming reasonableness. It felt really bold and heavy.
If people agree, we can wait until we need to update the screenshots for some other reason before merging this. Sorry I didn't figure this out while the discussion about the referenced commit was going on.
I'm not 100% certain how many fonts support each symbol. Please try it out and let me know if it doesn't work for you.
Compare after:
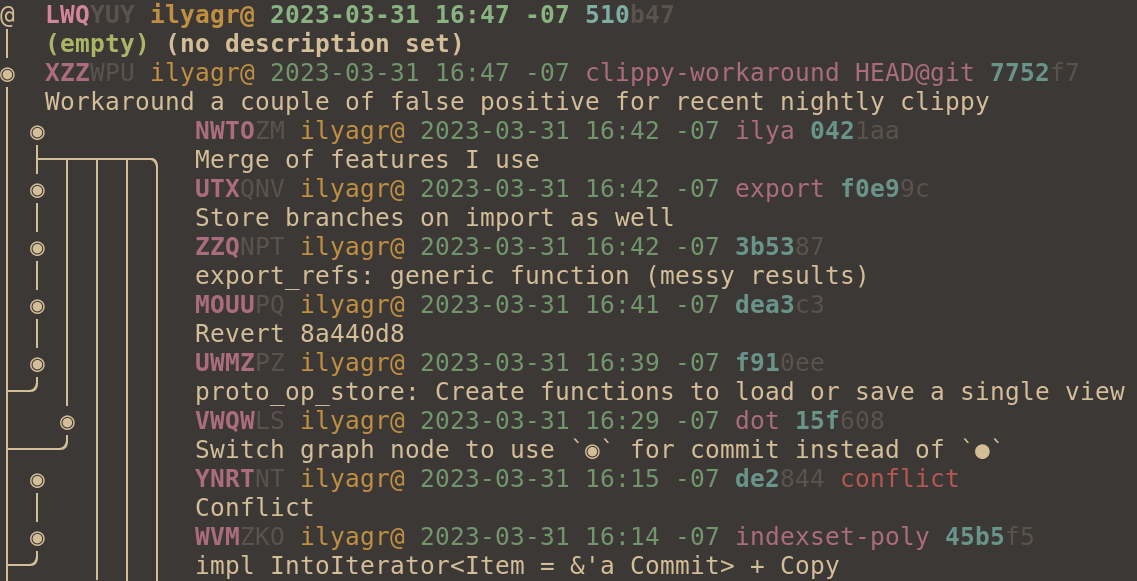
and before:
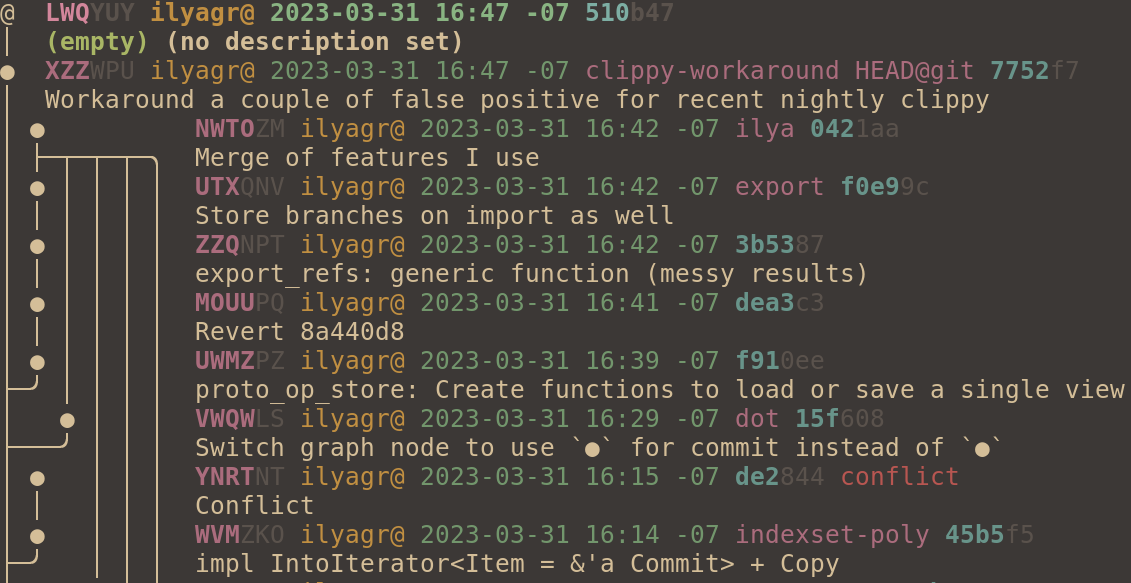
Since resolve_symbols() now removes Present(_) node, it make sense to
handle symbol resolution error there. That's why I added a "pre" callback
to try_transform_expression().
Perhaps, "operation" scope (#1283) can be implemented in a similar way,
(but somehow need to resolve operation id and call repo.reload_at(op).)
This makes it clear that RevsetExpression::Present node is noop at the
evaluation stage.
RevsetEvaluationError::StoreError is unused right now, but I'm not sure if
it should be removed. It makes some sense that evaluate() can propagate
StoreError as it has access to the store.
I'm going to split RevsetError into symbol resolution and evaluation errors,
and evaluate_revset() is the only place where CLI crate explicitly specifies
RevsetError type.
I want to adjust --sample-size while running slow revset benchmarks. The
baseline option seems also useful.
Short options are derived from Criterion::configure_from_args().
If you set e.g.`ui.pager = 5`, we currently ignore that and fall back
to the default. It seems better to let the user know that their config
is invalid, as we generally do. This commit does that. With this
change, the error message will look like this:
```
Config error: Invalid `ui.pager`: data did not match any variant of untagged enum CommandNameAndArgs
```
Maybe the key name will be redundant once the `config` crate releases
a version including https://github.com/mehcode/config-rs/pull/413
(thanks, Yuya).
The `Repo` is a higher-level type that the index shouldn't have to
know about. With this change, a custom revset implementation should be
able evaluate the revset on a server without knowing which repo it
refers to.
We already pass a `CompositeIndex` to
`default_revset_engine::evaluate()` so let's use that wherever we
currently use `repo.index()`. That will help us remove the `repo`
argument, and it will also let us internal types (like `IndexEntry`)
in the index methods we call.
I'm about to replace the `&dyn Repo` argument by several smaller
types, and it's easier to collect those in a single context type than
to pass them separately as arguments.
I also moved `revset_for_commit_ids()` and `take_latest_revset()` onto
the new type because it was easy. `build_predicate_fn()` and
`has_diff_from_parent()` ran into some lifetime issue when I tried.
The `public_heads()` revset only contains the root commit in
practice. I'm not sure what we want to do about phases, but since we
don't have any real support for them yet, let's just remove this
revset. I didn't update the changelog because we don't seem to have
documented the revset function (and it seems unlikely that users who
found out about it found it useful enough to use it when they could
just use `root`).
The `ProtoOpStore` was separated out to simplify the migration from
Thrift. Now that the `ThriftOpStore` is gone, we can inline
`ProtoOpStore` as the TODO says.
The impact of not having configured one's name and email is not apparent from the warning message. Under the Toulmin model:
- Claim (implicit): You should configure your name and email.
- Grounds: Your name and email are not currently configured.
- Warrant (currently missing): Configuring your name and email will let you do...
Some benchmark numbers in the following order:
- original
- fresh repo, BatchSize::SmallInput
- fresh but index-preloaded repo, BatchSize::SmallInput
- fresh but index-preloaded repo, BatchSize::LargeInput
% cargo run --release --features bench -- bench revset ':main'
revsets/:main time: [271.49 µs 271.74 µs 272.07 µs]
revsets/:main time: [754.17 µs 758.22 µs 764.02 µs]
revsets/:main time: [367.11 µs 372.65 µs 381.99 µs]
revsets/:main time: [341.76 µs 342.98 µs 344.35 µs]
% cargo run --release --features bench -- bench revset 'author(martinvonz)'
revsets/author(martinvonz)
time: [767.43 µs 770.52 µs 775.59 µs]
revsets/author(martinvonz)
time: [31.960 ms 31.984 ms 32.011 ms]
revsets/author(martinvonz)
time: [31.478 ms 31.538 ms 31.615 ms]
revsets/author(martinvonz)
time: [31.503 ms 31.526 ms 31.550 ms]
I think the fresh but index-preloaded repo is close to the practical
evaluation environment. With BatchSize::SmallInput, it appears to consume
~600MB (RES) memory (compared to ~50MB in LargeInput.) I don't think that's
huge, but it might affect cache usage, so I chose LargeInput.
https://docs.rs/criterion/latest/criterion/enum.BatchSize.html
{kind=link}
{kind=link}